We report here some preliminary results obtained by using by using the features Average log envelope (ALE) and Average instantaneous frequency (AIF) at the output of several fixed bandpass filters on noisy Aurora speech database. These preliminary results indicate that the ALE and AIF features that we advocate are atleast as good as traditional features based on MFCC (Mel-frequency cepstral coeffecients) filterbank and its relatives. Thus we are hopeful that with our current adaptive filterbank based feature extraction methods and with the improved signal and interference separation, we can easily improve the recognition performance significantly.
Experiments with the aurora 2 database were
conducted to determine the level of robustness for mismatched
conditions, i.e. when the models were trained on clean speech and
tested on noisy utterances. By holding the back-end constant, we
ensured that any increase in the word accuracy when compared with the
standard methods was due to our front-end processing techniques. The
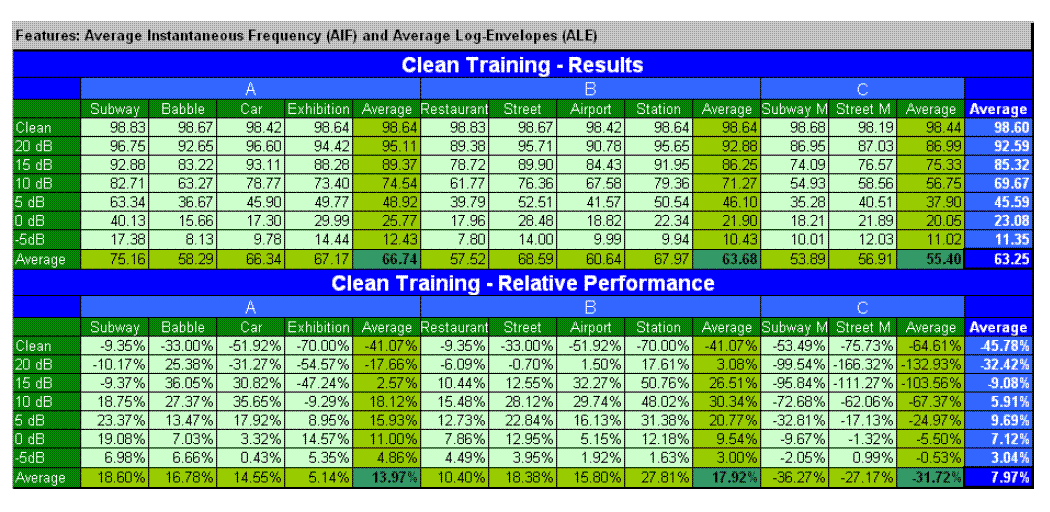
results are tabulated in the following figure.
The top panel shows the word accuracy rate and the bottom panel shows
the performance of our method when compared with the standard
Mel-cepstrum front-end with 3 mixture HMM back-end, set by European
Telecommunication Standards Institute (ETSI) STQ-Aurora group. Negative
sign impiles poorer performance. The results indicate a substantial
improvement for certain tasks, especially for SNRs of 0 to 15 dB.
Average recognition rates showed improvement for every task
in sets A and B. Accuracy rates for set C were a bit
disappointing, underperforming the standard set by the reference
front-end. This poorer performance is probably because of mismatched
channel conditions. This should be rectified if we track the
formants using our current feature extraction methods. As shown in the
table overall accuracy rates (last line) our method improved by an
average of 13.97% for set A and by 17.92% for set B and by -31.72% for
set C. The overall accuracy rates for clean training
improvement using our features is 7.97%.